simplify neural nets with pruning and compression
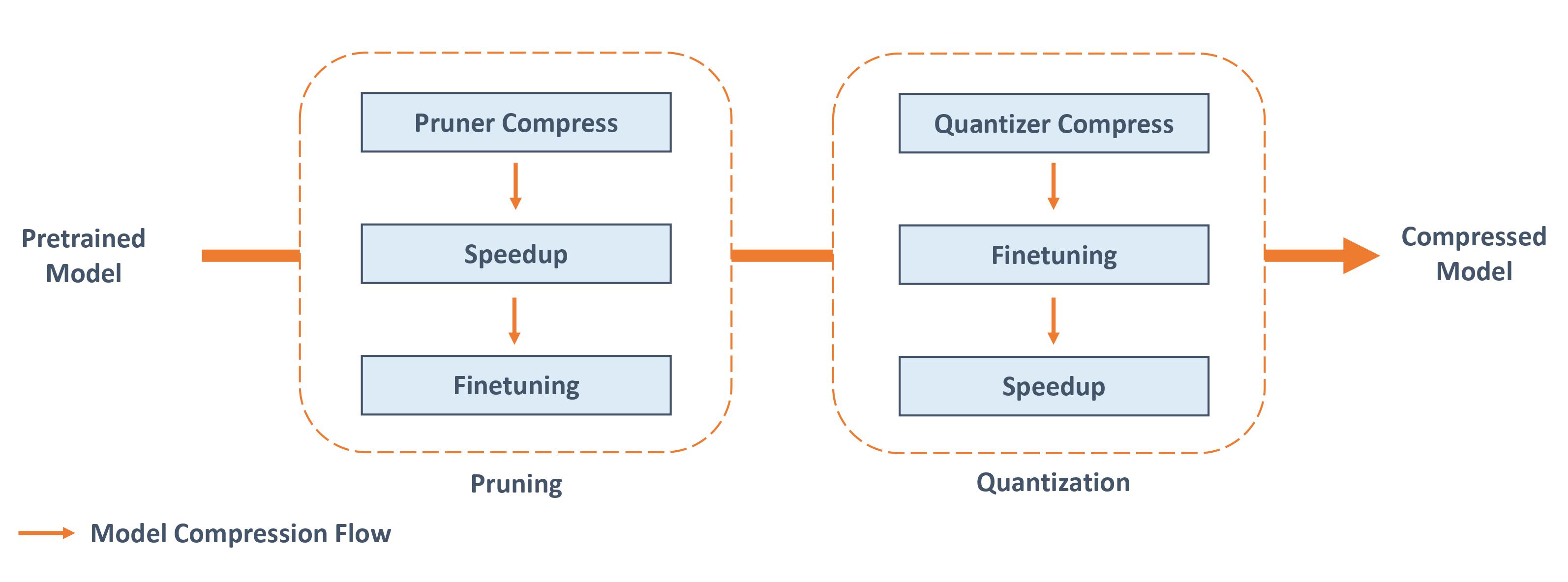 Compression pipeline in NNI
Compression pipeline in NNI
Pruning
Cut off the params from the weights, bias, and kernel values by changing values to null and leave out these connections from the network. However the data structure remains as it is. So memory and compute are the same.
Compression
Takes the pruned model and removes the pruned params.
Let's use nni (neural network intelligence) for these steps.
nni has modules called pruning and speedup.
The pruner takes a config list (dict) with options to include modules to compress like layers, sparse ratio of the pruning targets.
To prune the params we'd to use compress method that returns a data structure called as masks which has info about pruned params.
Now to remove these pruned params we need to use a speedup module.
We need to provide a model, samples and masks.
This will make the model really small and execute faster.
Here's a quickstart guide for nni.