model serving system 101
models are only useful if they can make predictions in real-time, is reliable, at low latency and at scale. even the best model is useless if users wait 5 seconds for getting recommendations. this will impact user experience.
beyond this, systems need SLAs, A/B tests, shadow tests and the serving infra should handle concurrent requests, sudden events, model configurations like machine types, instance counts, number of workers and threads.
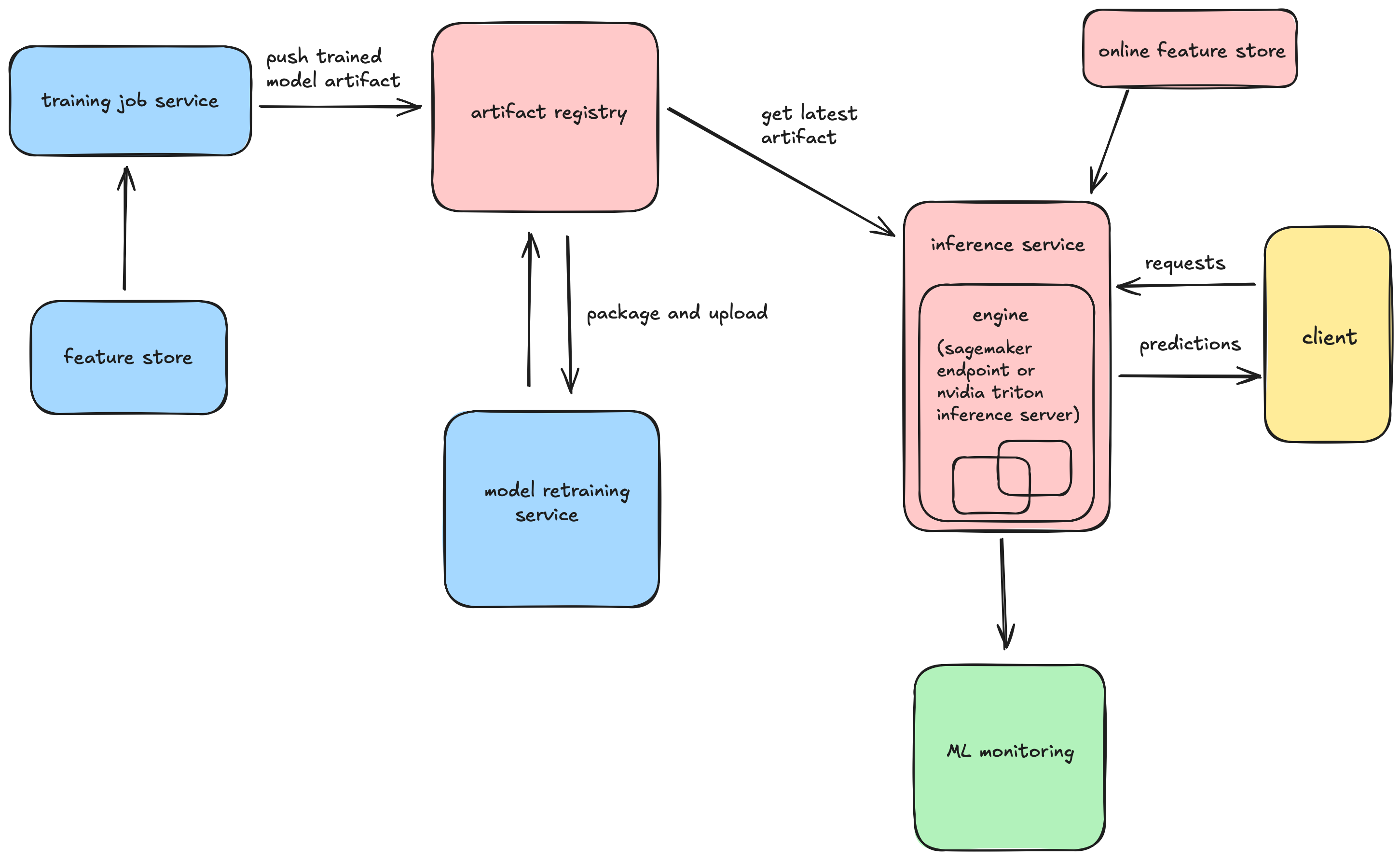
a model serving system has components like model packaging, serving endpoints, rollbacks, timeouts, continuous updates.
model packaging
once a model is trained you get an artifact. this include weights of a neural network, architecture, processing steps for running in production.
it involves two steps: serializing and containerizing.
serializing
a model artifact into a binary format which will be performant at real-time. onnx is very popular and framework agnostic. onnx runtime enables optimizations like graph fusion and supports pre-quantized models that will help improve latency and throughput.
containerization
artifact alone isn't enough to run inference - you need dependencies with it like python, pytorch, any processing or logging logic, CUDA kernels, model config. containerization bundles all these things into a docker image. this ensures the exact same environment in dev and prod. typically this image is pushed to AWS ECR and then inference service picks it up for serving.
inference service
now this service exposes the model endpoint. this endpoint can be managed (like a sagemaker inference endpoint) or a self-hosted (like a nvidia triton inference server running on our own machine)
this involves fetching the latest artifact, fallback approaches if something goes wrong. then there are timeouts (this is the latency budget we have) that we need to tune as per the model, expected load.
once you have a model running in prod it cannot serve requests forever. you need to retrain the model on new set of data to keep it up-to-date with new patterns. it can be a periodic (daily, weekly) job that does this. ml engineers also work on new features or a new architecture and this can be a new model altogether.
typically we evaluate the new model by carrying out shadow or A/B tests.
in shadow tests we run the new model in production in parallel to the actual serving model. we route the same requests to the main model as well as to this shadow model. the main purpose is to compare latency, error rates, and prediction quality between the two models without impacting any users.
whereas in A/B tests small percentage of real traffic is routed to the new model.
all the requests-responses and other metrics are logged and analyzed later to see if the new model is performing better or not.
also once you want replace the main model with the new one you do it gradually by routing 20% first and then gradually increasing. one example can be 20% - 50% - 80% - 100%.
we always prefer a load test first to understand the infra requirements of the model like the memory it consumes, its latency, does it have a cold start issue (when the first request is slow because the model needs to be loaded into memory, which we solve by pre-warming) and then we move on to the shadow tests. if everything works great we carry out AB tests for weeks.
there are many more challenges that come in picture when keeping the serving systems healthy.
autoscaling
when there are events that can be predicted (holidays or upcoming movie) or unexpected events (covid) there can be sudden increase in demand (increased RPS) then the model endpoints should be able to scale up and down accordingly.
monitoring model drift
you need to continuously monitor model performance or retrain the model on a repeated schedule.
logging and monitoring
any spike on the dashboard needs to be investigated, by tracing logs across inference service, and model code. you need to look into metrics like CPU/GPU utilization, memory utilization, RPS, p95/p99 latencies, error rates, etc.
fallbacks
when a fallback is triggered (model inference timeouts, NaNs in predictions, or infrastructure failures) the system needs a strategy to still serve something useful. this could be:
- returning cached predictions from the last successful request
- using a simpler backup model
- serving rule-based results (trending content or some globally popular items)
the choice depends on the use case. for search, returning no results is often better than irrelevant ones. for recommendations, showing global popular content is better than a blank screen.
rollbacks
a new model might have high latency or high error rate in production and if this happens we need to rollback to a previous healthy version of the model. you might store these versions in s3 or in some registry. typically triggered automatically when error rates exceed thresholds or p99 latency got worse.
maintenance
you need to maintain runbooks for the issues you think might occur in production. logging should be structured which can help engineers debug. there are other housekeeping things like cleaning up unused resources in non-prod environments, ensuring you have alerts in place. if there are any models which are not active and there's no traffic coming towards it then it needs to be de-registered to save incurring costs. periodic updates to services are needed as well.
ml platform teams are always looking at cost—unused resources and over-provisioned models add up quickly. you need to do frequent cleanups like unused resources, model that are not optimized for the traffic they get. e.g. over-provisioned instances, underutilized GPUs.
usually there are on-call engineers who need to take up this housekeeping tasks, monitor service related dashboards, if there are any latency or error rate spikes then they will debug and act on it as required.
ml serving systems are the backbone of the product. you can build great models but the serving systems should enable fast and reliable predictions to give users what they actually need without impacting behavior.