understand distributed model training
Once we have fully optimized our architecture, only then should we move towards distributed training
There are mainly 2 parallelism paradigms:
1. Model parallelism
A straightforward way to do distributed training is to divide the ops into smaller sets so that they can be executed on different devices. Still, ops usually depend on each other (forward and backward pass), making it difficult to implement.
So to resolve this we can use: an inter-layer strategy
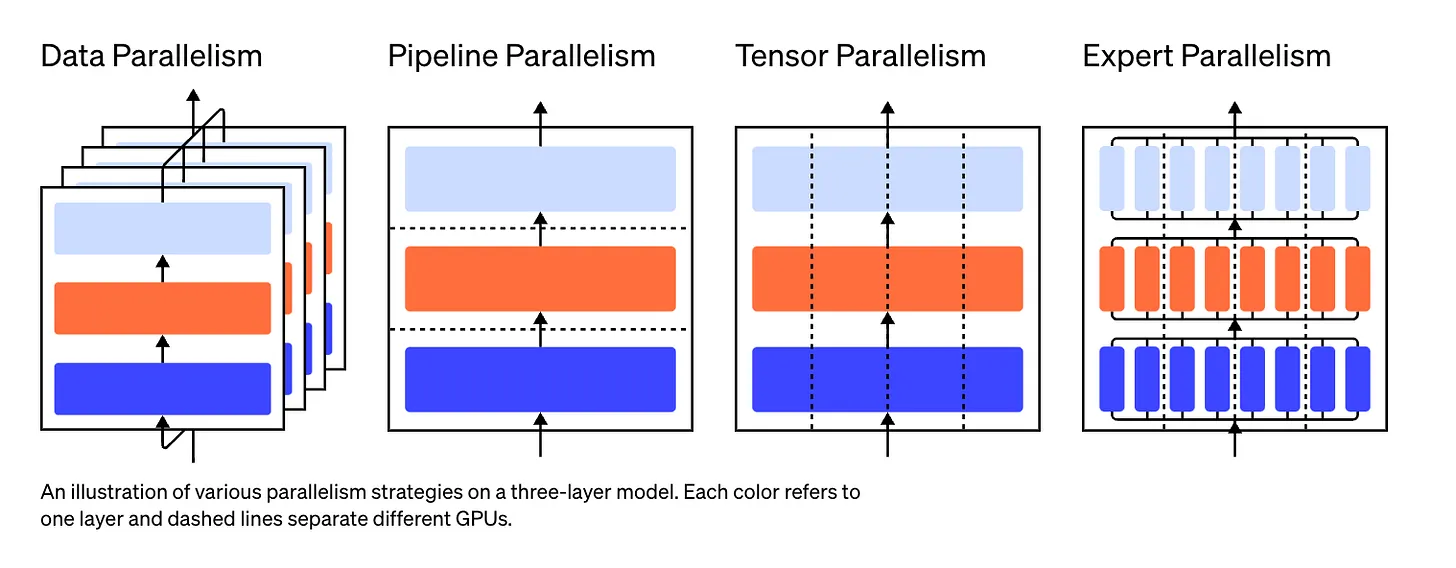
Inter-layer strategy (pipeline parallelism) In this strategy, each model layer is executed on a different device in parallel.
Inter-operation strategy We divide operations that are executed on each layer into smaller chunks.
Intra-operation strategy (tensor parallelism) Executes part of the same operation on different devices.
2. Data parallelism
Divide the training dataset into smaller sets and then use these sets to train distinct replicas of the model.
At each step, we'd synchronize gradients across devices. this phase is the key to the data parallel approach.
This synchronization phase can be implemented using approaches like parameter server (one server aggregates the gradients, calculates the average gradient and sends them to all the training servers but this may become a major bottleneck operation) or all-reduce.
Using a data parallel approach is very popular but with large language models coming into the picture we are shifting to other strategies to efficiently train these huge models.
We can see how these large language models are trained on multiple GPU-enabled clusters with FSDP or DeepSpeed.
@Lilian Weng has an in-depth blog post on these strategies.